Disclaimer: I was not able to complete this challenge entirely within the duration of the competition, despite getting painfully close to retrieving the flag before giving up. It was not until I checked an event write-up by Galhacktic Trendsetters that I realised I was on the right track all along and was able to retrieve the flag within 15 minutes.
The original challenge can be found on the 2018 Google CTF website, and was solved by 47 teams by the close of the competition. In this miscellaneous-category challenge titled “feel it”, a zip archive is available for download, with the description “I have a feeling there is a flag there somewhere”. The title of the challenge can usually be a cryptic clue, but at this point there isn’t much to go off – perhaps “feel” refers to the Unix command touch, which changes the timestamp on a file. We will see shortly exactly what this refers to.
Downloading the file, we can start inspecting it to get an idea of what it might be. The seemingly random 32-byte filename is probably unrelated to this challenge as all other challenges I had attempted so far followed this pattern. I ignored it, assuming it could be related to some kind of meta-challenge. After extracting the archive, we find an extensionless file named “feel-it”. Executing file feel-it tells us that it is most likely a pcapng file, which is used by Wireshark for capturing traffic of packet-based communications protocols. This piqued my interest in the challenge as I work with Wireshark on a near-daily basis. You can view this capture in your browser with CloudShark if you’d like to follow along.
Immediately upon opening the file in Wireshark I notice that the packets are not the usual Ethernet I am familiar with, but USB packets instead.

Using what little familiarity I have with USB, I know that the host needs to request device descriptors in order to enumerate the device. We can see exactly that request-response transaction taking place between the host and device 9 on bus 1 in packets 1 and 2 via endpoint 0 (the control endpoint, which exists for all devices). The response is much more interesting ; it should tell us the vendor and product ID, the device class, and the indices of the manufacturer, product, and serial number string descriptors (for further interrogation by the host).
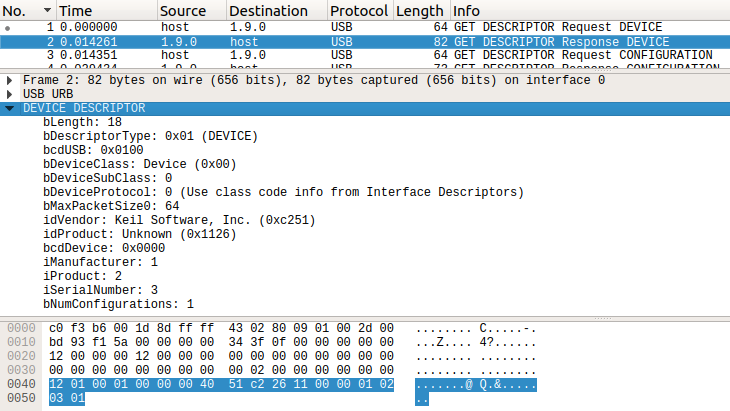
The device class, subclass, and protocol (bDeviceClass, bDeviceSubClass, and bDeviceProtocol) are the null triplet, which simply refers us to the interface descriptors to locate the actual device class information. We can take a look at those later. For now we note that the index of the manufacturer, product, and serial number strings (iManufacturer, iProduct, iSerialNumber) are 1, 2, and 3, respectively. These will be important shortly when we inspect the string descriptors.
The Vendor ID and Product ID (idVendor and idProduct) are 0xC251 (Keil Software Inc.) and 0x1126 (Unknown). Coming from an embedded systems background and recognising Keil (now owned by ARM), I reasoned that the author of this challenge must have been using a Keil microcontroller development board to generate the traffic. I dismissed this important clue and set myself back by a few hours chasing a red-herring.
The host then requests the device’s configuration descriptor set. The host does not yet know what to expect from the device, so it requests the the first 9 bytes (the first configuration descriptor only, which is a fixed size) in packet 3, and performs an additional request in packet 5 using the size returned by the response it received in packet 4 (25 bytes). The response to the second descriptor response encapsulates the configuration, interface and endpoint descriptors.
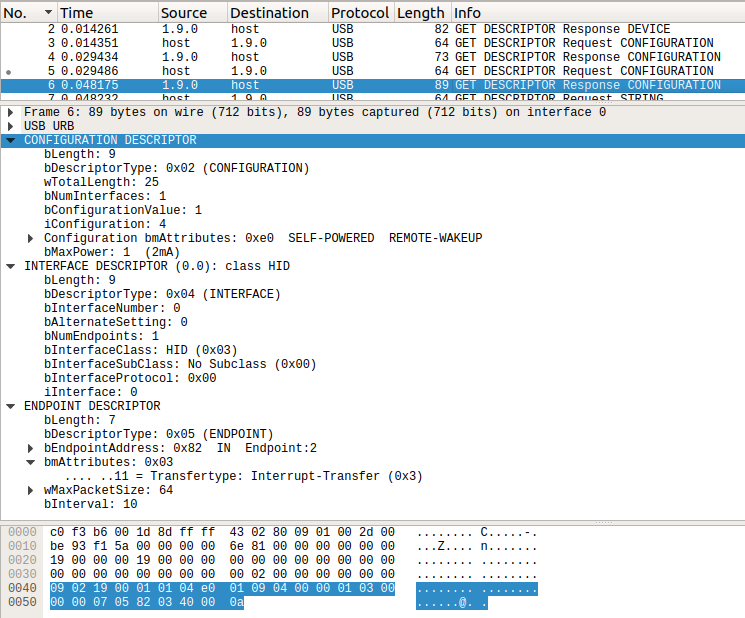
We can now confirm from the interface descriptor that interface of device 9 on bus 1 is a USB Human Interface Device (HID), and that the device expects the host to communicate with this interface via endpoint 2 using the interrupt transfer type in the direction of device to host (in addition to the existing control endpoint, endpoint 0). Contrary to the terminology used by the USB standard, the device isn’t actually interrupting the host, but the host is polling the device at regular intervals – a protocol typically used by keyboards and mice. If you’ve ever seen a gaming mouse that claims to have a 1 kHz polling rate, this is what that is referring to.
Next up, after querying the supported language codes, the host queries the manufacturer, product, and serial string descriptors using the indices provided in the device descriptor earlier. We see that someone has intentionally obfuscated some information from us here – the strings returned are “Manufacturer is confidential”, “and so is product string”, and “not to mention serial number”.
Finally, the host requests that the device now use configuration 1 as reported in the configuration descriptor set, and device enumeration is completed. At this point the operating system knows everything it needs in order to select the appropriate driver to load, but as will be seen later, this is probably not exactly the case here.
The host then does something odd in packet 17 – it queries the string descriptor at index 4, but the device never informed the host of its existence. I can only assume that this was a manual request initiated by the author of the challenge in order to stimulate the desired response from the device, was manually inserted into the packet capture for the purposes of providing a clue, or is part of some library code that interacts with this device.
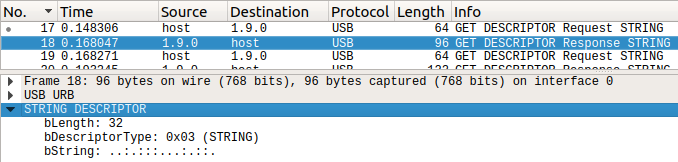
The device replies with the cryptic string “..:.:::…:.::.”. What is that? Stumped, I Googled this sequence and found a twitter post with similar period & colon combinations, accompanied by mentions of Braille in the confused comments. My own confusion increased as I know Braille is written with 6 or 8 dots in a vertical 2×3 or 2×4 arrangement. This sequence, and the ones in the twitter posts are arranged in the wrong direction and never contain dots in the upper position only, due to the lack of an upper period character. Regardless I attempted to interpret this as Braille by grouping the characters in groups of three, and rotating them to the vertical orientation, unsuccessfully.
After reading more about Braille, I learned that digraphs/trigraphs and abbreviations are used to shorten words, so it’s feasible that a flag could be encoded in such a short sequence of characters. I spent hours attempting to decode this string thinking it would lead somewhere and still have yet to figure out whether or not it means anything. I can only assume the commenters in the twitter thread were trolling each other and they were all talking jibberish. Regardless, this clue gives context to the title “feel it”, which now obviously refers to the tactile nature of Braille. Combining this clue with the hint before that we might be looking at keyboard data, we might assume that the device with bus ID 1.9.x is a Braille keyboard.
The Braille keyboard theory seemed like a good one, but I needed more information. I recalled that the Linux USB command lsusb lists USB devices using the USB vendor and product IDs formatted as VID:PID in hexadecimal. It was worth a shot searching online for the string C251:1126 and seeing what I could find. To my surprise, I not only turned up some GitHub results, but they belonged to a Google project, BrailleBack – a background service for Android devices that interfaces with refreshable Braille displays and keyboards. It turns out that this project is based on BRLTTY – the same concept, but for access to the Linux terminal.
Specifically, I found out from the driver code that we are dealing with a EuroBraille Esys device, which is a family of refreshable Braille displays with integrated Braille keyboard, ranging in size from 12-80 Braille cells wide. Recall earlier I said that this device probably doesn’t load a kernel-mode driver. It appears to interact directly with an application (brailleback / brltty) via libusb.
The host requests each of the string descriptors again before resetting the device in packets 29 & 30, and requesting the configuration descriptor set once more in packets 31 & 32. I’m not entirely sure why the host does this but I assume it’s due to an application attempting to interact with the device.
The remainder of the bus traffic consists of two transaction types; USB Request Block (URB) Interrupt and SET_REPORT.
URB Interrupt is the previously-mentioned polling of endpoint 2 by the host. The packet capture shows this traffic occuring bidirectionally – initially only from host to device in packets 33-40, then both from device to host and host to device, starting at packet 43, when the reply to query in packet 33 comes back from the device. I believe the reason for this latency between host and device is simply due to the nature of Interrupt transfers – the host must schedule them well ahead of time to ensure that the bus is guaranteed to be free when the actual interrupt transfer takes place.
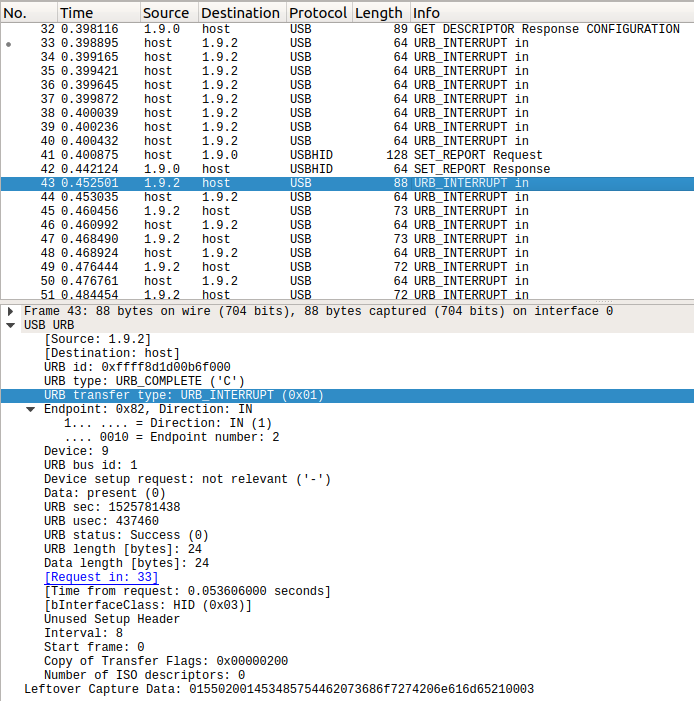
Most of the fields in this packet are not that special, but one field contains interesting data. Wireshark labels this as “Leftover Capture Data” but it is really just the payload, containing device-specific data that Wireshark doesn’t know how to decode. The URB Interrupt transfers from host to device don’t contain any useful information, so I apply the display filter “usb.capdata” in Wireshark to view only the device-to-host interrupt transfers, and also set up a custom column so we can see all the data simultaneously.

Packet 43 is somewhat unique, containing the string: “SHWTF short name!”, which I have not been able to determine the exact meaning of. I though perhaps it had something to do with DOS 8.3 filenames. We also notice a pattern where the first byte is sequentially increasing, always followed by the constant bytes 0x55, 0x02, 0x00, and the data always terminates with the byte 0x03. Unfortunately this data is constant for the remainder of the packet capture and so looks to be a dead-end. This leaves just SET_REPORT as the only part of the capture remaining to be investigated.
SET_REPORT is typically used by keyboards to change the status of their status LEDs. I applied the display filter usb.data_fragment and again, a custom column to show all the data on-screen together and there’s quite a bit of it. These are requests from the host to the control endpoint (endpoint 0) but we can’t see all of the data at once within Wireshark alone. I exported all the data using tshark -r "feel-it" -T fields -e usb.data_fragment | awk NF > data-fragment.hex and began analysing.
Each data fragment is 64 bytes in size, and I noticed every second data fragment (after ignoring the first) is the same constant sequence – 24 0x00 bytes, a single 0x03, and 42 0x55 bytes. I realised that this is probably a single transaction split over two packets. The 0x55 bytes appear to be padding, and the 0x03 byte appears to be the same terminator we saw earlier in the URB Interrupt packets. I remove these, in addition to the first 5 bytes which are the constant sequence {0x02, 0x00, 0x54, 0x42, 0x53} for all the remaining packets.
tail -n +2 data-fragment.hex | paste -s -d' \n' | tr ':' ' ' | sed -r "s/02 00 54 42 53 (.*) 03( 55)*$/\1/g" > display-data.hex
This leaves exactly 80 bytes per packet, which matches up with the information we previously learned about the device being a EuroBraille Esys display, which has a maximum of 80 Braille cells in the largest model. At this point I think we can consider each byte to be an individual Braille character. It seems likely that the 0x00 bytes are just blank characters on our display, so to make things more readable, I remove all the nulls with sed -r "s/(.?)( 00)*$/\1/g" display-data.hex, leaving us with the following:
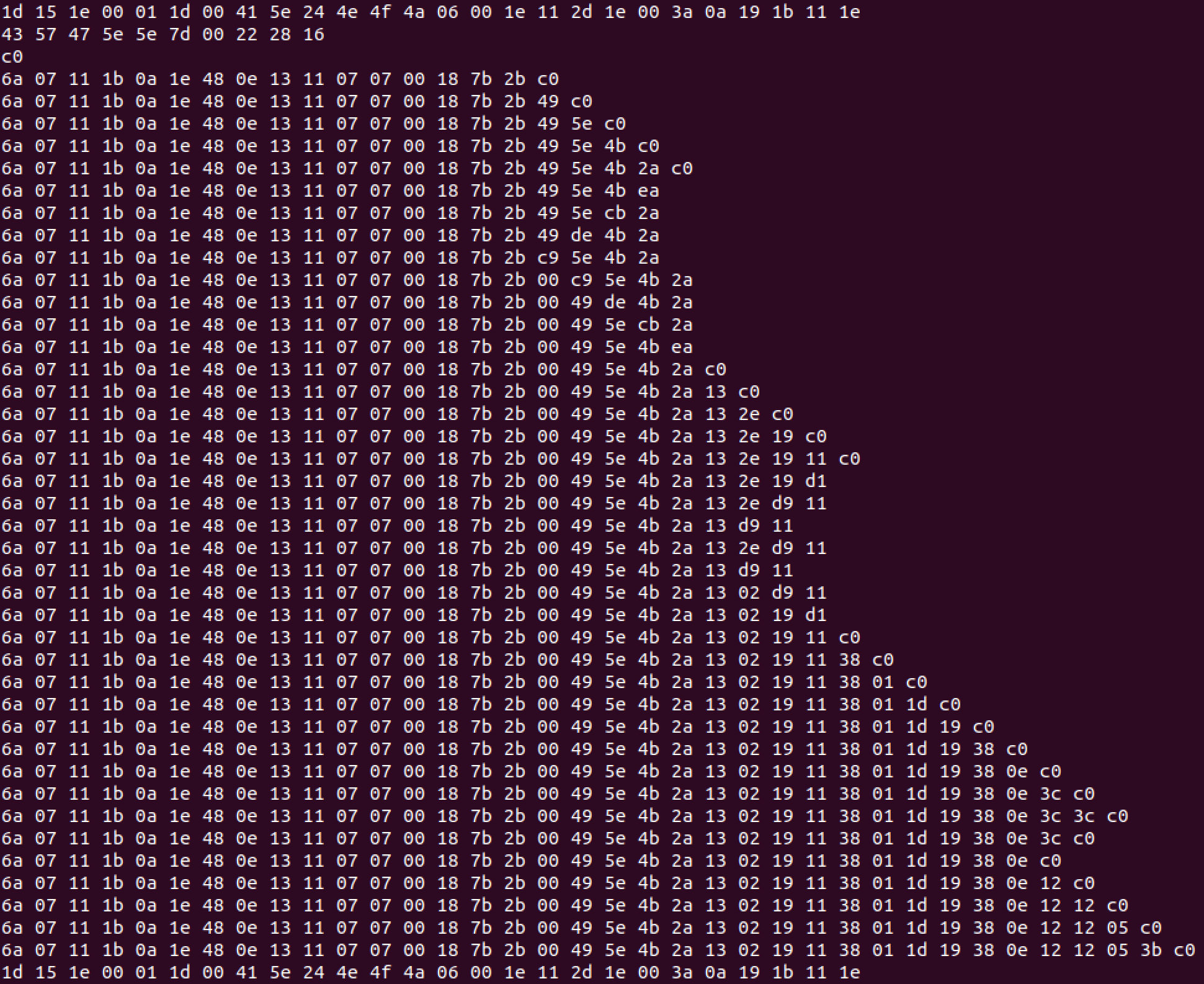
Note how each subsequent line contains mostly the same data as that which appears prior, with only a few bytes being appended at a time – it’s not difficult to imagine that this might be display data being sent to the refreshable Braille display several characters at a time. The question remains then, how is the data encoded?
 First of all, let’s talk about how Braille symbols are identified. Because the 6-dot Braille standard was implemented before the advent of 8-dot Braille, and 8-dot Braille includes the 6-dot patterns as a subset, the numbering of dots is ordered as follows: dot 1 in the top-left, dot 2 in the upper-middle left, dot 3 in the lower-middle left, dot 4 in the top right, dot 5 in the upper-middle right, dot 6 in the lower-middle right, dot 7 in the bottom left, and dot 8 in the bottom right. The mapping of Braille symbols to letters and numbers defined differently by many standards, so we have to try a few.
First of all, let’s talk about how Braille symbols are identified. Because the 6-dot Braille standard was implemented before the advent of 8-dot Braille, and 8-dot Braille includes the 6-dot patterns as a subset, the numbering of dots is ordered as follows: dot 1 in the top-left, dot 2 in the upper-middle left, dot 3 in the lower-middle left, dot 4 in the top right, dot 5 in the upper-middle right, dot 6 in the lower-middle right, dot 7 in the bottom left, and dot 8 in the bottom right. The mapping of Braille symbols to letters and numbers defined differently by many standards, so we have to try a few.
We expect the flag to be encoded in the format CTF{...}, so rather than attempt to decode the entire dataset, I’ll just try searching for sequences that match that pattern. Initially I tried the Braille ASCII encoding – in this encoding, all 64 possible combinations of the first 6 Braille dots are represented as ASCII codes 0x20 to 0x5F. The Braille cells representing lowercase letters a-z map to the ASCII codes for uppercase A-Z, and uppercase letters or numerals are encoded with a prefix of either ⠠ (dot-6), correpsonding to ASCII ‘,’ (0x2C) for capitalisation, or ⠼ (dots-3456), corresponding to ASCII ‘#’ for numerals. Numerals use the Braille ASCII codes for a-j, but have their dot positions shifted down one place. This actually corresponds to mapping the ASCII numerals 1-9 to the Braille numerals 0-8, and ASCII 0 to Braille ASCII 9 (it’s a weird encoding). With this knowledge in mind, we can rule out Braille ASCII as the encoding using, since it should translate the ASCII “CTF” in upper or lower-case to the same 3 byte sequence {0x44, 0x54, 0x46} (plus optional uppercase prefix), which does not exist in our dataset, else we would have seen the string “CTF” in plaintext in the Wireshark capture.
We also know that the EuroBraille Esys has 8-dot Braille cells, which the Braille ASCII encoding does not allow for, so whatever encoding is used has to have provisions for those. I came across the Braille Computer Notation (BCN) which allows for 8-dot patterns, however the ASCII codes for alpha-numeric characters map directly to codes for BCN symbols, which means we would have seen those in our dataset as plaintext also.
After more research I came back to the Unicode Braille Patterns at codepoints 0x2800-0x28FF. This encodes all 256 possible dot combinations available in an 8-dot Braille cell, so it seems like the ideal encoding for our data. First let’s try directly encoding “CTF”.
| ASCII | Braille | Unicode Braille | UTF-8 |
| ‘c’ | ⠉ (dots-14) | U+2809 (0x09) | 0xE2 0xA0 0x89 |
| ‘t’ | ⠞ (dots-2345) | U+281E (0x1E) | 0xE2 0xA0 0x9E |
| ‘f’ | ⠋ (dots-124) | U+280B (0x0B) | 0xE2 0xA0 0x8B |
| ‘C’ | ⣉ (dots-1478) | U+28C9 (0xC9) | 0xE2 0xA3 0x89 |
| ‘T’ | ⣞ (dots-234578) | U+28DE (0xDE) | 0xE2 0xA3 0x9E |
| ‘F’ | ⣋ (dots-12478) | U+28CB (0xCB) | 0xE2 0xA3 0x8B |
It wouldn’t make sense to encode the 0x2800 offset for every character, so I assumed that only the second byte would be transmitted, i.e. we are looking for either the sequence {0x09, 0x1E, 0x0B}, or {0xC9, 0xDE, 0xCB}. Unfortunately I wasn’t able to find either of these sequences within the dataset. If you already know the solution to this challenge then you can probably see my error here – I have the wrong encoding for the uppercase characters. The reason this happened is that when you hover your cursor over each Braille symbol in the Unicode table at the Braille Patterns page on Wikipedia, it gives an excerpt from the corresponding page for the 6-dot Braille symbol, regardless of whether or not dot-7 or dot-8 are set in the highlighted symbol; I was wrongly assuming that the uppercase characters had both dots-78 set, rather than just dot-7.
I was starting to get desperate so I again turned to the BRLTTY driver code and found a file mapping every combination of dots to a byte code, which didn’t match any of the existing standards I had found. Unfortunately I didn’t realise that this code was for a completely different device manufactured by BrailCom – I figured the name was common to all Braille devices in BRLTTY. I spent a long time trying to work with the information in that file but never got anywhere, and eventually gave up. The competition was over and I had failed.
Several days passed and I was able to read Galhacktic Trendsetters’ writeup. I realised while reading their solution that their process was almost identical to everything I had done. I stopped reading after they mentioned a comment in the BRLTTY driver code regarding Braille cell bit ordering, which matched my previous assumption (Unicode encodes them as 0x2800 + the dot value in binary, with dot 1 being the MSB). I resumed the challenge, knowing I would no longer be able to claim the points, but perhaps I could still figure this thing out on my own.
I got lucky and stumbled upon different code pages for the uppercase letters than the first time. In my first attempt I had represented the Braille symbols for “CTF” as {0xC9, 0xDE, 0xCB}, but this time I instead used {0x49, 0x5E, 0x4B} and immediately found the byte sequence I was looking for. The problem is that the Unicode standard doesn’t actually define the mapping between Braille symbols and their meaning.
We could solve the challenge by hand at this point, by assuming that the byte values can be decoded to Unicode Braille symbols with their MSB representing dot-1 and their LSB representing dot-8, and then looking up those Braille symbols. It turns out the Braille symbols map to English text more-or-less according to the Braille ASCII code. I extracted the flag by hand but that felt a bit anti-climactic, so I wrote a get-flag script. The script simply parses the hex dump we produced earlier and translates first to Unicode Braille symbols, then to ASCII characters.
#!/usr/bin/env python3
from time import sleep
d = dict(zip(range(0x2800, 0x2900), list(" a1b\'k2l@cif/msp\"e3h9o6r^djg>ntq,*5<-u8v.%[$+x!&;:4\\0z7(_?w]#y)= A1B\'K2L@CIF/MSP\"E3H9O6R^DJG>NTQ,*5<-U8V.%[$+X!&;:4\\0Z7(_?W]#Y)=")))
for i in range(0x2800, 0x2900):
d.setdefault(i, chr(i - 0x2800))
f = open('display-data.hex', 'r')
for idx, line in enumerate(f.readlines()):
braille = u''
text = u''
for b in list(memoryview(bytes.fromhex(line.strip().replace(' ', '')))):
o = 0x2800 + b
braille += chr(o)
text += d[o]
print('{}\t{}\n\t{}\n'.format(idx, braille.strip(), text.strip()))
sleep(0.1)
The script outputs each line in both Braille and ASCII, and we can see the line of text gradually being typed out as it was entered into the terminal.
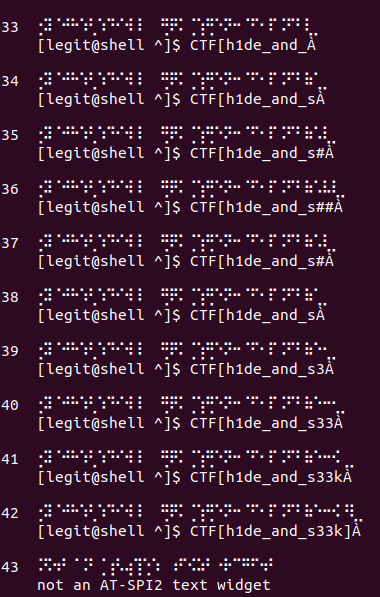
And there it is, albeit slightly off – the flag is CTF{h1de_and_s33k}. You may be wondering what those extra characters are – it appears that the user’s cursor is encoded as ⣀ (dots-78), even if the Braille symbol underneath the cursor already uses those dots. Dots-78 just happens to map to À (Capital A with Grave) since I had unknown characters in the dictionary and simply used the index of these characters as their value.
This challenge forced me to learn a lot more about refreshable Braille displays then I ever cared to know, but it also helped strengthen some USB concepts. If I had tried rubber-ducking the problem then I probably would have solved it whilst the competition was still running – I’m looking forward to more challenges like this in the future and it seems that challenges involving reverse engineering of packet captures do make an occasional appearance.
P.S. Please let me know if you know what the hell “..:.:::…:.::.” means!
